1. Instalación de Ollama
curl -fsSL https://ollama.com/install.sh | sh
Ollama permite a instalación de varios modelos de intelixencia artifical xenerativa
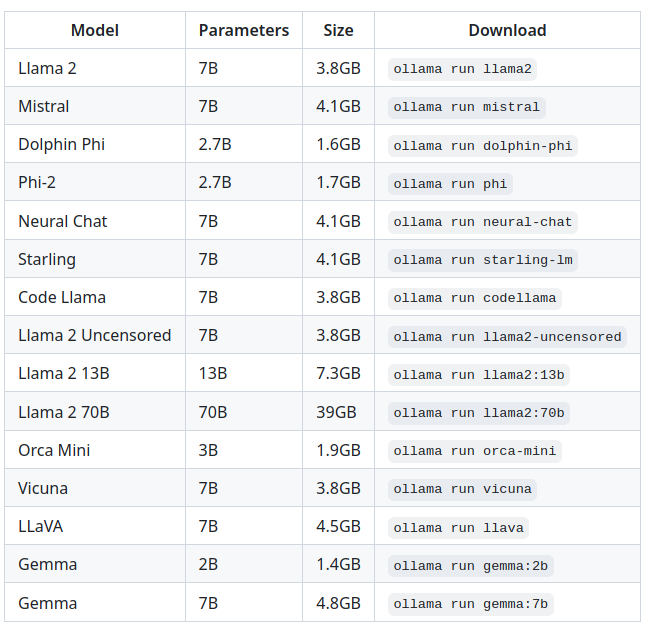
E para probalos co terminal é tan sinxelo como escribir algo así:
ollama run gemma:2b
Sen embargo vexamos como se instala unha aplicación para facelo desde o navegador:
2. Instalación de Docker
sudo apt update
sudo apt install apt-transport-https ca-certificates gnupg2 software-properties-common
curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/debian $(lsb_release -cs) stable"
sudo apt update
sudo apt install docker-ce
sudo groupadd docker
sudo usermod -aG docker usuario
3. Instalación de Ollama-webui
As instrucións para a súa instalación e personalización no caso de dispoñer dunha gpu ou desexamos acceder ao servidor desde a rede, podemos atopalas aquí. Pero para unha instalación básica nun equipo local, pode facelo do seguinte xeito:
git clone https://github.com/ollama-webui/ollama-webui
cd ollama-webui
docker compose up -d --build
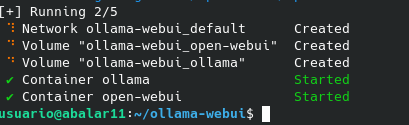
Unha vez que remate a descarga desa máquina docker podemos acceder ao aplicativo escribindo no navegador:
http://localhost:3000
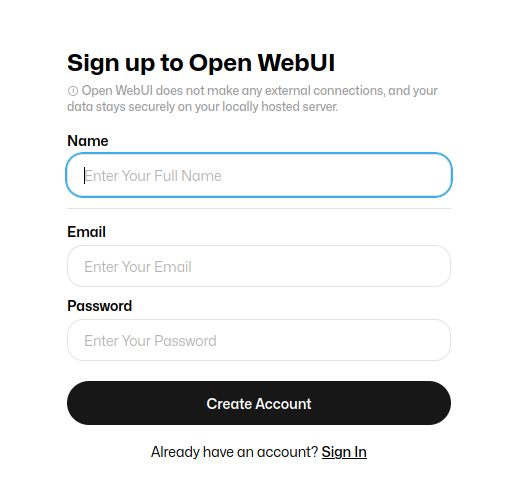
E procedemos a rexistarnos coa nosa conta de correo electrónico, premendo en Sing up:
4. Configuramos o webui
Prememos no botón de configuración

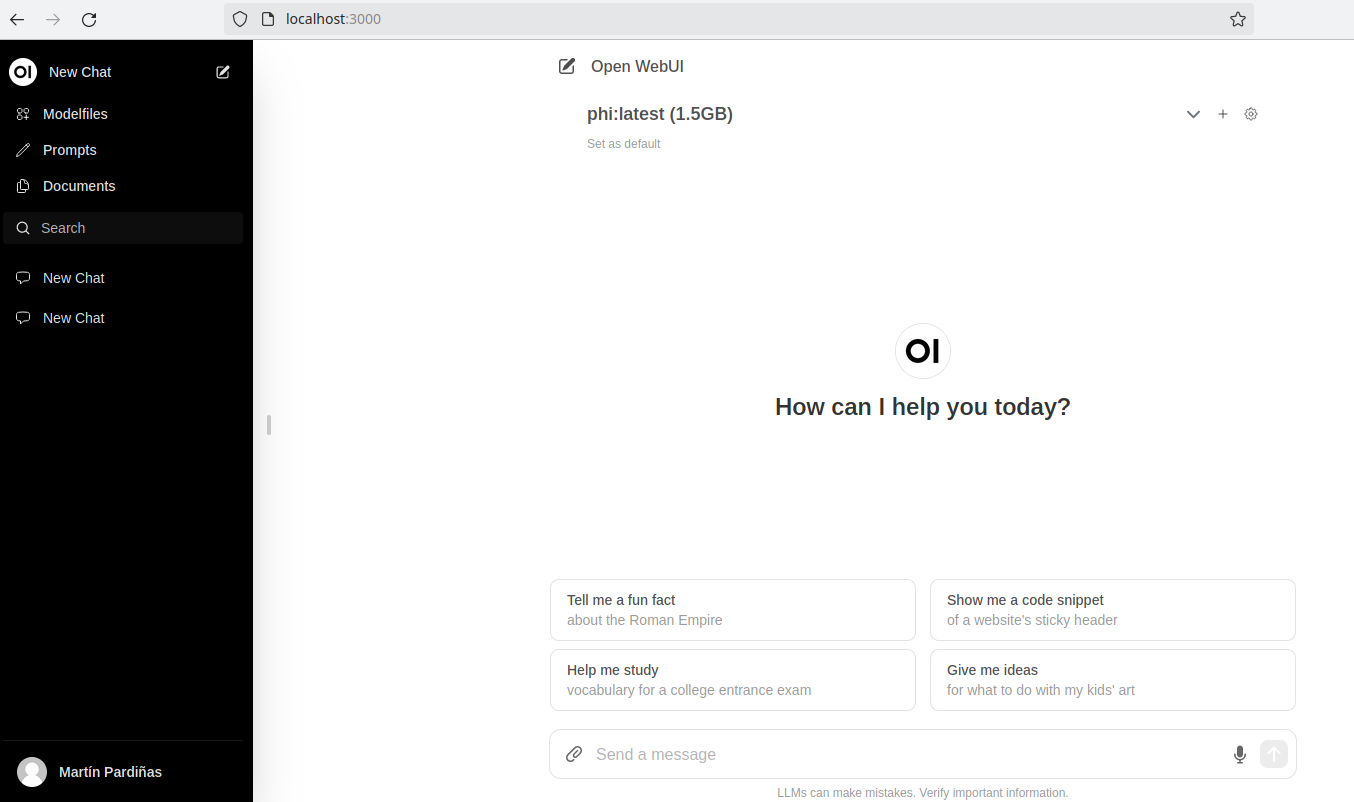
E configuramos o modelo co cal desexamos traballar (ver táboa no inicio deste artigo). Tarda un tempo en descargar en función da conexión que dispoñamos:
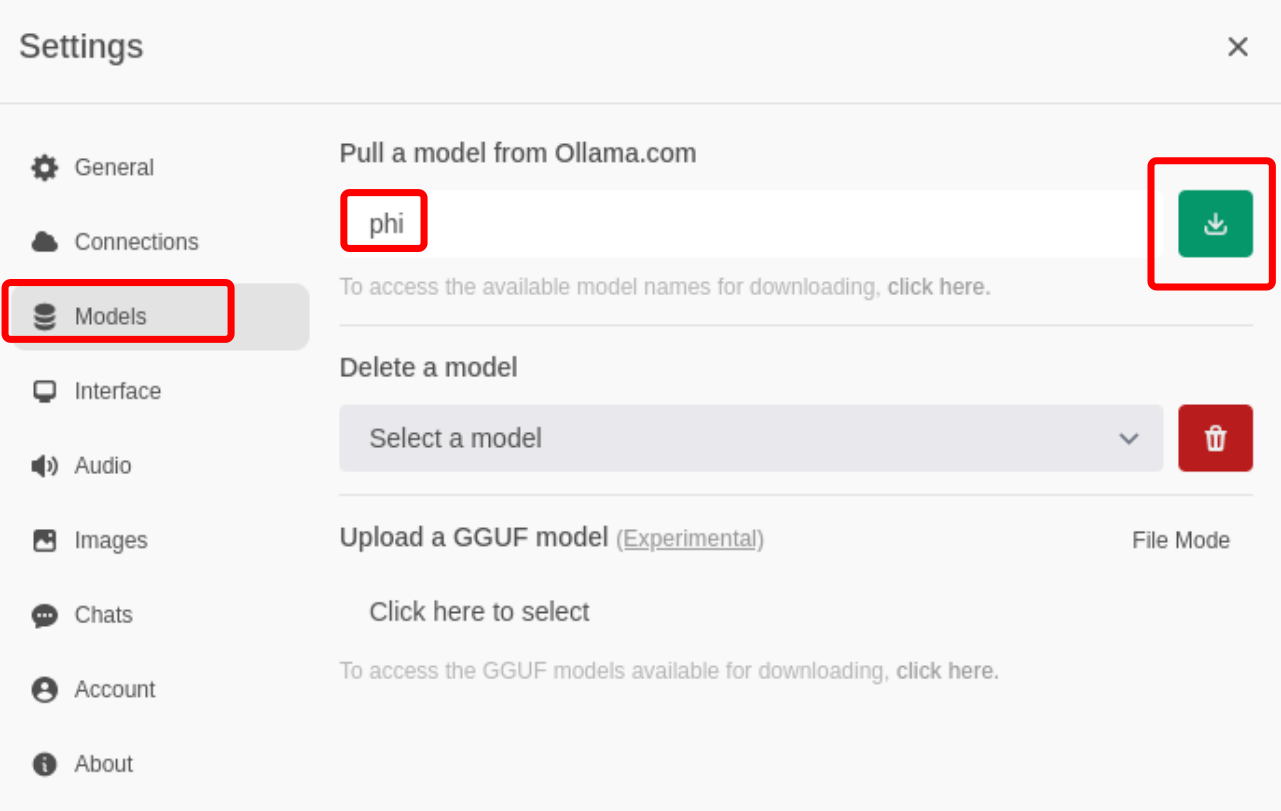
Se o equipo é pouco potente é mellor empregar o modelo máis pequeno o Gemma:2b.
Seleccionamos o modelo, e xa podemos comezar a enviar prompts á intelixencia artificial