¿Cómo entienden el texto los ordenadores?
Para entenderlo mejor, es interesante que comencéis viendo el siguiente vídeo.
Cuando hablamos del lenguaje, debéis recordar que las redes neuronales siempre usan números para sus neuronas de entrada, realizan algunos cálculos basados en los parámetros entrenados y dan como resultado otros números.
Podemos resumir la historia de los LLM o Modelos de Lenguaje Largos en 3 generaciones:
-
Primero se entrenaron las Redes Neuronales con caracteres: Había 26 caracteres (tamaño de una red de neuronas pequeño y manejable usando el idioma inglés) y se trabajaba con pocos pesos para predecir el siguiente carácter. Ojo, cada carácter se representaba por un número y la red de neuronas de entrada, ofrecía 26 números en sus neuronas de salida, siendo el número más alto, el correspondiente a la predicción de la letra más probable. El desafío era poder aprender como una serie de caracteres se convertía en una palabra y sobre todo, su sentido. Demasiado pedir!
-
Después se entrenaros con palabras (palabra por palabra y a cada palabra se le llamó token), se incluían todas las palabras del diccionario y esto implicaba nombres, y el modelo comenzó a entender que cada palabra se asociaba con un contexto. Inclusive, en un idioma hay nombres inventados y debería haber tokens especiales para palabras inventadas. Estos modelos tenían limitaciones, se tuvieron que omitir palabras raras, lugares especiales, etc.
-
En la época del Chat GPT se hizo un descubrimiento, un gran avance: había un término medio entre esos dos extremos, se podrían formar fragmentos de letras que a veces formarían una palabra completa y a veces serían partes de una palabra. Y a este fragmento se le llamó token. Esto hizo que se pudieran manejar nombres de lugares y nombres propios, dividiéndolos en tokens más pequeños y además, se podía trabajar con la raíz de una palabra (pasar de singular a plural, de masculino a femenino, etc). Se acercó más a como aprendemos, con prefijos, sufijos, etc.


Los
modelos de lenguaje de gran tamaño procesan texto utilizando tokens ,
que son secuencias comunes de caracteres que se encuentran en un conjunto de
texto. Los modelos aprenden a comprender las relaciones estadísticas entre
estos tokens y se destacan en generar del siguiente token más probable en una
secuencia de tokens.
Podéis utilizar el tokenizador de OpenAI para comprender cómo un modelo de lenguaje puede tokenizar un fragmento de texto y el recuento total de tokens en ese texto.
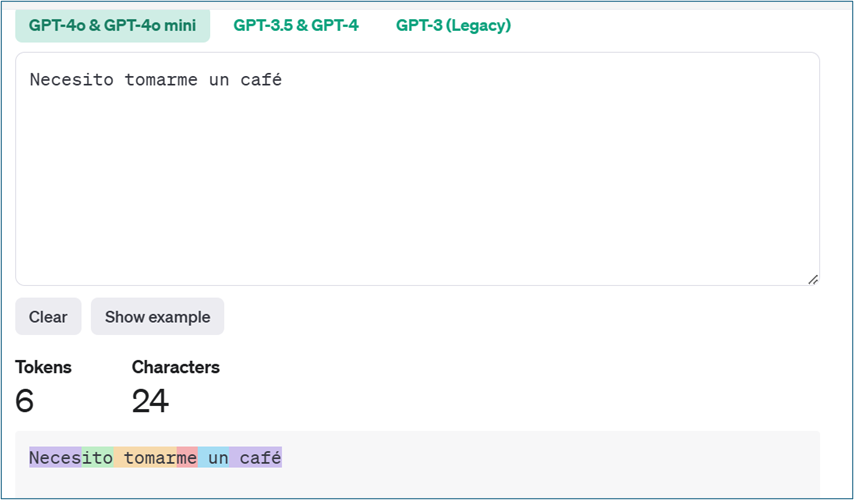
Hay una regla general:1000 tokens es aproximadamente 750 palabras (en inglés)
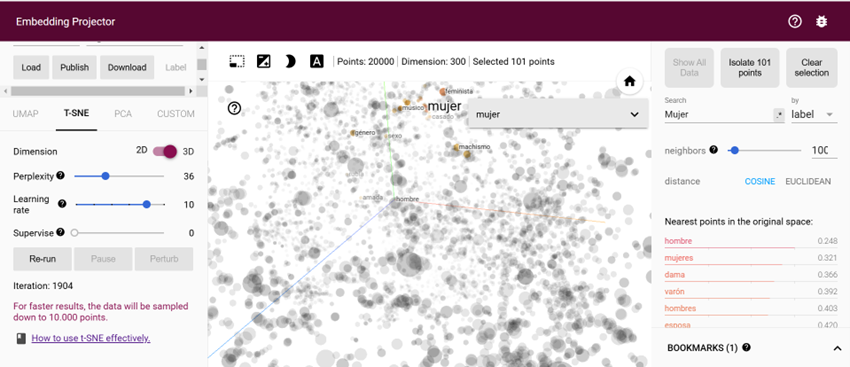
El embedding podemos definirlo como el proceso de convertir las palabras o caracteres (tokens) a vectores (que no son más que números) en un espacio de alta dimensión, capturando relaciones semánticas y permitiendo que el modelo procese el lenguaje de manera más efectiva.
Existen varias técnicas para calcular los vectores embeddings a partir de texto. La más usada es Word2Vec (word to vector). Si entráis en el siguiente link y empezáis a jugar, podéis ver que las palabras con relación semántica como "alumno" con "alumnos" se encuentran representadas muy cerca.